
Il 3 giugno scorso è stato presentato, presso l’International Conference on Advanced Information Systems Engineering, il paper “LOD Publication in the Archival Domain: Methods and Practices” curato da Fabiana Guernaccini, Silvia Mazzini e Giovanni Bruno, nell’ambito del workshop “Open Data and Ontologies for Cultural Heritage” (ODOCH). I risultati di ODOCH sono disponibili online, pubblicati da CEUR Workshop Proceedings.
Il workshop ha rappresentato un momento molto stimolante di confronto con le altre realtà che si occupano di pubblicazione di Linked Open Data e di valorizzazione del patrimonio culturale, a livello nazionale e, soprattutto, internazionale.
Attraverso l’illustrazione di casi d’uso virtuosi promossi da istituzioni che da diverso tempo hanno scelto la via dei Linked Open Data per promuovere e comunicare il proprio patrimonio informativo, abbiamo cercato di raccontare le ragioni che spingono le istituzioni culturali a scegliere di pubblicare i propri dati attraverso l’uso delle tecnologie semantiche e i vantaggi derivanti da questa forma di condivisione.
Perché dunque un istituto culturale dovrebbe scegliere di pubblicare LOD? I motivi sono molteplici, e certamente tra questi spiccano usabilità, ricercabilità, reperibilità e interoperabilità delle informazioni nonché la possibilità di diventare fonte autorevole di dati che possono essere riutilizzati dalla comunità. L’applicazione delle tecnologie LOD al patrimonio culturale consente di migliorare, arricchire e promuovere la diffusione delle informazioni e aumentare il potenziale informativo della conoscenza.
Dalla diffusione delle tecnologie Linked Data ad oggi abbiamo assistito ad una proliferazione di progetti per il patrimonio culturale che hanno abbracciato questa filosofia. Tuttavia la reale consapevolezza delle potenzialità legate a queste tecnologie da parte dei promotori risulta limitata ai soli benefici derivanti dall’immediata visibilità. Purtroppo sono ancora pochi gli istituti coinvolti in un processo di produzione e fruizione di Linked Open Data di più ampio respiro, che siano consapevoli dell’utilità e dei benefici acquisiti in un arco temporale medio-lungo. Tra questi esempi, spicca certamente per lungimiranza il caso dell’Istituto per i beni culturali della Regione Emilia-Romagna che, con esperienza quasi decennale di pubblicazione di Linked Open Data per i beni culturali, è stato fonte di ispirazione per diverse applicazioni sviluppate da start-up e società che in tempo reale restituiscono informazioni sul patrimonio emiliano-romagnolo.
L’applicazione delle tecnologie LOD al patrimonio culturale consente di migliorare, arricchire e promuovere la diffusione delle informazioni e aumentare il potenziale informativo della conoscenza.
I principali esempi di pubblicazione LOD hanno alla base una valutazione attenta delle ontologie utilizzate per esporre i dati. Nel mondo dei Linked Open Data infatti le ontologie rivestono un ruolo fondamentale, poiché disambiguano la semantica dei dati identificando in modo univoco i concetti, così da impedire una attribuzione di significato arbitraria, permettendo la diffusione e creazione di nuova conoscenza, scopo ultimo del Semantic Web. Per facilitare la realizzazione di tale obiettivo è fondamentale il riutilizzo, laddove possibile, di ontologie già esistenti come raccomandano le Best Practices emanate dal W3C per la pubblicazione di dati su Web.
Non sempre però le ontologie già pubblicate sono in grado di rappresentare in maniera granulare e specifica il proprio dominio di interesse, per cui diventa necessario integrare le ontologie esistenti o pubblicarne di nuove, allineandole a vocabolari già pubblicati per aumentare l’interoperabilità. Abbiamo cercato di capire se i modelli, i vocabolari e le ontologie più utilizzati per la descrizione del patrimonio culturale, e nel caso specifico del dominio archivistico, sia in ambito nazionale che internazionale, fossero sufficienti a rappresentare le esigenze descrittive degli istituti culturali: i modelli presi in considerazione sono stati scelti sulla base della loro rilevanza, della loro diffusione e del loro possibile sviluppo futuro. Questo elenco non è esaustivo e comprende CIDOC-CRM, Schema.org, Europeana Data Model (EDM), l’ontologia SAN e la versione draft di RIC-CM e RIC-O.
Dopo un’attenta analisi abbiamo deciso di riutilizzare OAD, l’ontologia per la descrizione archivistica sviluppata nel 2012 nell’ambito del progetto ReLOAD, avviato con l’obiettivo di sperimentare l’applicazione delle tecnologie del Web Semantico ai dati archivistici utilizzando, oltre alla stessa OAD, le ontologie EAC-CPF e OCSA, al fine di formalizzare un modello condiviso per la descrizione archivistica.
Col passare degli anni però le esigenze descrittive si sono modificate e affinate, rendendo OAD inefficiente nell’identificare e rappresentare la distinzione tra risorsa archivistica oggetto della descrizione e descrizione della risorsa stessa, spingendoci quindi ad una riflessione sull’opportunità di un aggiornamento dell’ontologia. Il risultato di queste considerazioni è la nuova release di OAD, il cui reference document e la rappresentazione grafica sono consultabili all’indirizzo http://culturalis.org/oad/.
Nel corso del tempo la risorsa archivistica può essere descritta da più strumenti di ricerca, può subire incrementi ed essere soggetta a revisioni. Da qui deriva la necessità di separare l’oggetto dalla sua descrizione consentendo così di collegarlo a molteplici descrizioni: secondo Michetti, Pearce-Moses, Prom e Timms «[i]n the digital era, many orders are possibile, and there may be no single original order»[1].
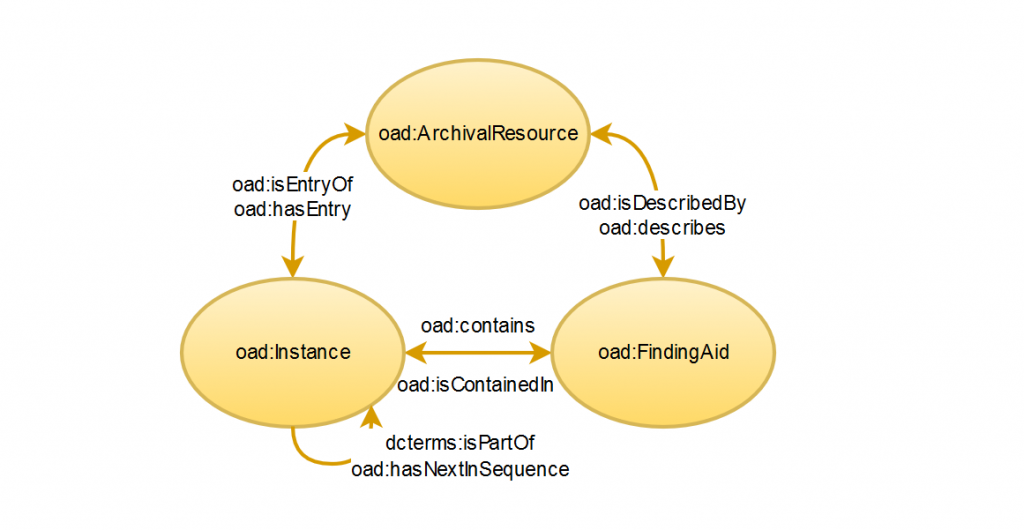
La classe oad:ArchivalResource è la “Unit of description” di ISAD definita come «[a] document or set of documents in any physical form, treated as an entity, and as such, forming the basis of a single description», mentre per la formalizzazione della classe oad:Instance ci siamo basati sulla definizione di “Archival description”: «[t]he creation of an accurate representation of a unit of description and its component parts, if any, by capturing, analyzing, organizing and recording information that serves to identify, manage, locate and explain archival materials and the context and records systems which produced it. This term also describes the products of the process». Entrambe le classi formalizzate sono collegate allo strumento di ricerca (oad:FindingAid).
In conclusione, l’ontologia OAD cerca, soprattutto in questa ultima release, di rispondere da una parte alle esigenze della tradizione archivistica nazionale e, dall’altra, di mediare con soluzioni internazionali non usabili, poco note o troppo poco specifiche.
Possiamo sintetizzare così le principali caratteristiche della nuova release di OAD:
- descrive il dominio archivistico in modo esaustivo;
- ha una rappresentazione molto semplice, ma che non ne limita la profondità;
- fa riferimento diretto allo standard ISAD;
- permette sia una descrizione di alto livello che più dettagliata e analitica;
- ha collegamenti semantici con altre ontologie di dominio;
- è già utilizzata da diversi istituti culturali italiani che pubblicano LOD;
- definisce una separazione tra l’oggetto della descrizione e la sua descrizione.
OAD quindi ha risposto alle richieste di modellazione degli istituti culturali e ha permesso l’esposizione dei dati archivistici sul Web, ponendosi come un tassello per il raggiungimento dell’arricchimento del patrimonio informativo, fine ultimo del Semantic Web.
[1] Giovanni Michetti, Richard Pearce-Moses, Chris Prom, Kat Timms, Role and meaning of arrangement and description in the digital environment, in Luciana Duranti, Corinne Rogers (Eds.), Trusting Records in the Cloud. The creation, management, and preservation of trustworthy digital content (2019).


